I write on my personal time. Feel free to buy me a coffee or buy a copy of TCP/IP Illustrated Volume 1 to learn more about the protocols that run the internet. Check out Wireshark Network Analysis for an awesome hands-on guide to wireshark.Network teams often use ICMP as a mechanism to determine the latency (propagation delay etc) and reachability between two endpoints using the trusty Ping utility. Ping appeared in late 1983 created Mike Muuss while working US Ballistics Research Laboratory. Additionally, what was interesting about 1983 is that it was the year the that the US military converged on IP (and TCP) mandating for any system connected to the ARPANET making Ping one of the oldest IP applications still in use today.
The naming for PING (Packet InterNet Groper) is a backronym for the sonar process used by submarines and other water-craft (as well as in nature). Which makes sense when you are trying to measure latency between nodes.
Ping uses ICMP (Internet Control Management Protocol echo(8)/echo-reply(7)) to communicate between nodes and is even mandated in the historic RFC1122 Requirements for Internet Hosts — Communication Layers(released in 1989) for internet connected hosts. This RFC is well worth a read to understand what was happening with IP and TCP in the aftermath of the congestion collapse events of the mid 1980s.
The problem with using Ping and ICMP as a measure of latency is that it is frequently blocked or placed in scavenger queues which distorts the latency detected (adding to it or making it appear jittery) anddoes not reflect the actual latency experienced by applications. The lack ICMP prioritisation makes sense, we want the actual user traffic coming through and processed at endpoints with a higher priority than our monitoring traffic. Secondly, Ping is usually run in intervals (eg. every 5 minutes) which means the that we wont be able to spot events between polling intervals.
This may have been good enough when we used IP networks for non-realtime applications (email and web browsing etc) where changes in latency and drops are not as important, but in the 2000s we started using IP SLA to inject synthetic traffic between to devices that support IP SLA and report on metrics like jitter and latency for the class of service or QoS markings desired. This was a good step further as now we understand how real traffic would perform while the IP SLA runs. This is (usually) run in intervals which means that still have gaps in our visibility. The good reason for using IP SLA (and other synthetics) is that traffic is being generated even when there is none being generated by users. A lot of vendors take this approach with their observability stacks, but it still leaves a gap between intervals and doesn’t necessarily reflect a users experience.
We can also monitor latency passively using captured TCP packets between nodes. NPM platforms like Alluvio AppResponse do this at a large scale, but we can also do this using Wireshark or TCPDump for ad-hoc reporting. The best bit is that we can now see the latency between any nodes that we can collect traffic between which has two big bennefits:
- We have every connection.
- It is all passive.
Using Wireshark we will look at how this is possible. I’ve talked about how TCP operates below the application layer and that an application has only a limited ability to influence socket behaviour. The OS kernel handles traffic acknowledgement, which has a very high priority in the Operating System scheduler. We can essentially ignore the TCP stack delay as negligible (unless it is behaving erratically which is a sign that the endpoint is over-subscribed).
The two TCP behaviours we will use to understand the latency of the connection are the 3-way handshake, and the TCP time to ACK two full segments.
Method 1 – The 3-way handshake
The 3-way handshake (also called connection setup time) is the process used to establish a reliable connection between two nodes. It involves the TCP client sending a specially marked segment called a SYN, The server responding with another specially marked segment called a SYN-ACK, followed by the client sending an ACK (with or without data). The delta between the SYN and the ACK collected anywhere between the nodes will give us the latency between the two nodes.

In this case we have a latency of 105ms between the SYN and the ACK. I’ve set the propagation delay of the backbone of this network to 100ms, which after we add small overhead on socket creation the server, we are very much right on the latency. I deliberately chose a capture that was was not on the client, or the server to show that this can be applied anywhere on the path.
We can also see this value of 105ms in each subsequent packet stored in the tcp.analysis.initial_rtt variable.

Method 2 — Time to ACK
We know that from RFC1122 we should see an ACK (for at least) every 2 full sized segments without delay, or after a packed marked with PSH is set. This behaviour is not impacted by the applications ability to process the data, and is solely the responsibility of the TCP stack in play. This method is best used close to the client (otherwise same additional math is required).


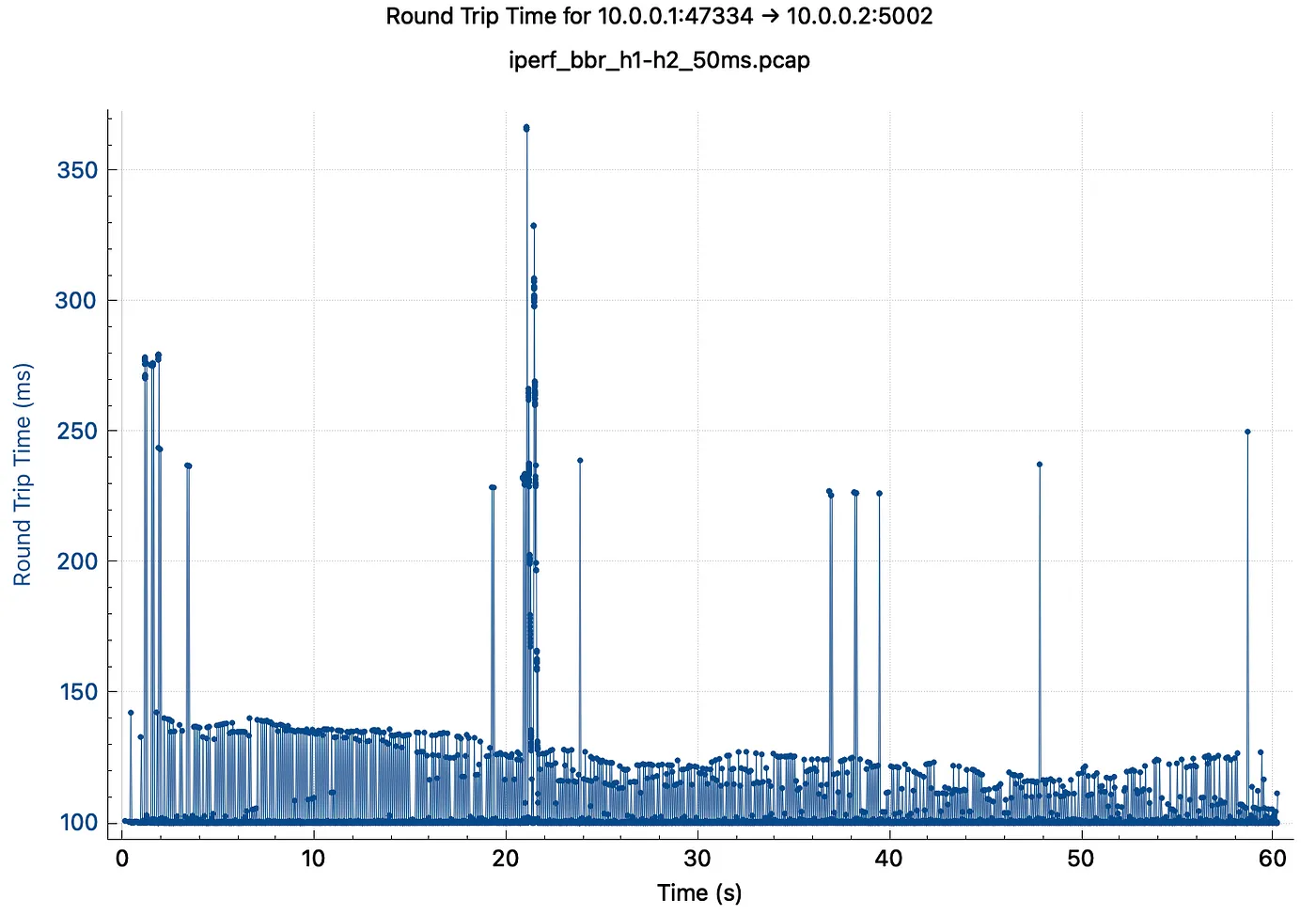
We can even graph this in Wireshark using the Round Trip Time option in the TCP Stream Graphs menu. You will also note some spikes in acknowledgements at and over 200ms, this is a topic willbe discussed in another article.

I like to add it as a coloumn in the packet list as below when troubleshooting TCP performance.

Using TCP to monitor latency has significant advantages over synthetics
If you made it this far, thanks for reading. Feel free to buy me a coffee or buy a copy of TCP/IP Illustrated Volume 1 to learn more about the protocols that run the internet. Check out Wireshark Network Analysis for an awesome hands-on guide to wireshark.
Leave a Reply